(1.4)面向对象概述之面向对象的基本概念和面向对象的思考方式
本文共 2236 字,大约阅读时间需要 7 分钟。
文章目录
1.“面向对象”思想的基本概念
- 类 Class
- 对象 Object
2.类与对象
-
类和对象,这两者之间的关系
有点像“先有鸡” 还是“先有蛋”的关系一样,有一点纠缠 从他们的定义就可以看出来: 用对象来定义类、用类来产生对象! 我们在学习本课程的时候,可以忽略这个问题 有的时候 在表达概念的时候,对象 与 类可以通用! 在设计软件系统的时候,对象是不存在的, 在软系统运行时, 在内存中创建对象。类不存在于物理世界 -
A class is a description of a set of objects that share the same attributes, operations,
relationships, and semantics “共享相同属性、操作、方法、关系或者行为的一组对象的描述符” -Rumbaugh -
An object is an Instance created from a class. 一个对象是根据一个类创建的一个实例
An instance’s behaviour and information structure is defined in the class. 类,定义了实例的行为和信息结构 Its current state (values of instance variables) is determined by operations performed on it. 对象的当前状态(实例变量的取值)取决于作用于该对象的操作
3.类的构成、对象的构成
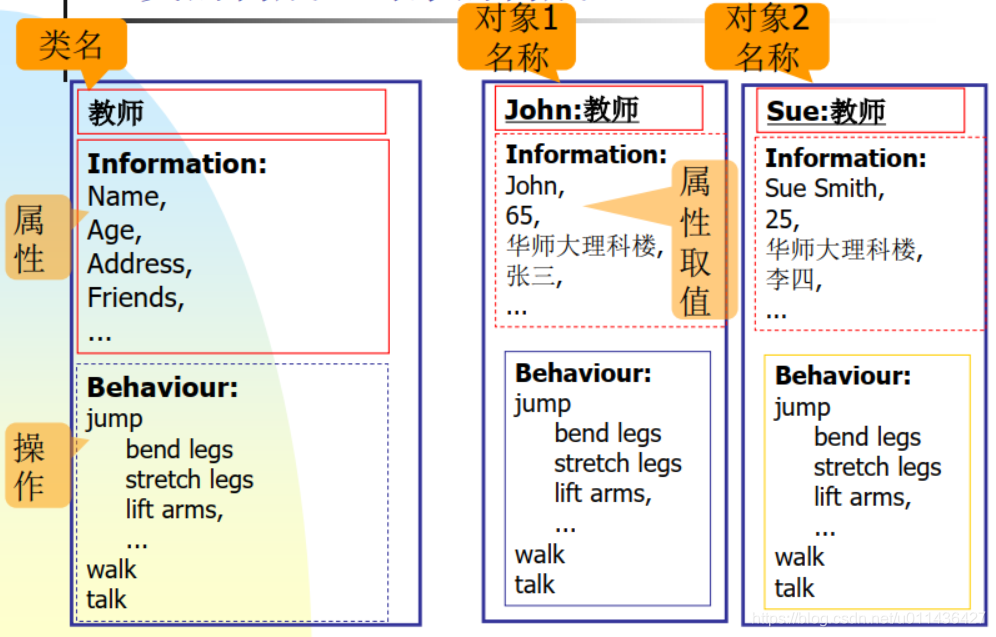
- 注意: 概念之间的互用 属性Attribute == 数据Data == 状态state == 信息information 操作operation == 方法Method ==行为behaviour = = 职责responsibility 对象object=实例instance
4.软件功能是如何完成的?
- 类 定义了对象群体的逻辑结构,包括属性和操作 系统运行时,类作为产生对象的模板,在物理层面是不存 在的
- 对象 系统运行时必须为每一个需要的对象分配内存、保存数据 对象存在于物理层面,每个对象都有自己的数据空间(内存) 所有的对象共享同一块代码空间
- 消息 对象之间的一种交流手段 就像我们日常工作中的各种交流手段
- 所有相关对象之间相互协作完成软件功能
5.面向对象的思考方式
-
软件工程是与人打交道的、是为人提供服务的
问题是什么? 谁碰到了问题? 问题的本质是什么? 问题该如何解决? -
对于想成为问题解决者的人来说,入门的关键是“把单一思维模式切换成多重思维模式”
-
“观察到的一切都是对象” – 这就是面向对象思考方式
-
软件系统是由多个对象组成,对象间通过消息相互交流、共同协作,以完成整个系统的功能
-
定义
在对世界/系统 进行 观察/建模的时候,把它们看成是由一系列相互交流、互为影响的对象集(a set ofobjects) 有两点含义: (1) 世界是由相互作用的对象组成的 (2)描述与构建由对象组成的系统 -
软件开发常规的两种思维方式:面向对象、面向过程
eg:流水生产线(面向过程)与一场篮球赛(面向对象)
-
C语言是一种面向过程的思维方式
程序的运行“一切尽在掌握中”:从main()函数的逐条语句开始执行、调用了子程序就必须一层层返回,最终又返回main函数; 系统需要完成的功能,分配到各个子函数,由main函数统一调度 -
比较
面向过程侧重于考虑方法的编写(哪个方法做什么事,不考虑所涉及的数据在哪里) 面向对象则致力于将数据和方法先做一个封装(分配一个对象做事,先考所需要的数据是否和它在一起) -
比较: 通信
(1)过程化解决方法通过信道传递数据,服务器端需要有专门的工具对接受的数据进行处理 (2)面向对象解决方法通过信道传递对象(数据+对数据的处理方法) 如, Web浏览器,接收到的Java Applet,就是一个对象。浏览器只要运行Applet里面的代码,就可以显示网页的内容 -
【误解】
对象包装(object wrap) : 把任意一段过程化的代码堆砌在一起 -
主要概念
面向对象分析 OO analysis, 面向对象设计 OO design, 设计模式 design patterns, 统一建模语言 the Unified Modeling Language (UML), 面向对象编程 OO programming, various OO programming languages, (1)C++/java/C#/.NET etc (2)and many other topics related to OO programming -
最重要的是:
以面向对象的思维方式去思考要解决的问题 how youthink in OO ways
6.面向对象的核心特征
- Following concepts are basics Object / Class Method / Message Encapsulation封装 Inheritance Interface / Implement接口 Polymorphism,多态 Composition / aggregation组合/聚合 Abstraction
- Advance OO concepts OO principle Design Pattern
转载地址:http://yryzz.baihongyu.com/
你可能感兴趣的文章
mysql 创建表,不能包含关键字values 以及 表id自增问题
查看>>
mysql 删除日志文件详解
查看>>
mysql 判断表字段是否存在,然后修改
查看>>
MySQL 到底能不能放到 Docker 里跑?
查看>>
mysql 前缀索引 命令_11 | Mysql怎么给字符串字段加索引?
查看>>
MySQL 加锁处理分析
查看>>
mysql 协议的退出命令包及解析
查看>>
mysql 参数 innodb_flush_log_at_trx_commit
查看>>
mysql 取表中分组之后最新一条数据 分组最新数据 分组取最新数据 分组数据 获取每个分类的最新数据
查看>>
MySQL 命令和内置函数
查看>>
mysql 四种存储引擎
查看>>
MySQL 在并发场景下的问题及解决思路
查看>>
MySQL 基础架构
查看>>
MySQL 基础模块的面试题总结
查看>>
MySQL 备份 Xtrabackup
查看>>
mYSQL 外键约束
查看>>
mysql 多个表关联查询查询时间长的问题
查看>>
mySQL 多个表求多个count
查看>>
mysql 多字段删除重复数据,保留最小id数据
查看>>
MySQL 多表联合查询:UNION 和 JOIN 分析
查看>>